

原文:When AI builds itself — Anthropic Institute
作者:Marina Favaro, Jack Clark | 发布于 2026 年 6 月
一句话总结
Anthropic 用自己内部的硬数据证明了:AI 正在加速 AI 的开发,而且加速度本身也在加快。从外部基准测试到内部工程效率,所有曲线都在上扬。递归自我改进——AI 完全自主地设计和开发自己的继任者——还没有实现,但可能来得比大多数机构准备好的时间更早。
进化的五个阶段
Anthropic 把这个过程分成了五个阶段:
| 阶段 | 时间 | 人类在做什么 | AI 在做什么 |
|---|---|---|---|
| 人工驱动 | 2021–2023 | 写代码、写文档 | 不存在 |
| 聊天助手 | 2023–2025 | 主导一切工作 | 生成代码片段,人类复制粘贴 |
| 编程 Agent | 2025–2026 | 审查和引导 | 独立写文件、编辑代码 |
| 自主 Agent | 今天 | 设定目标 | 自己跑代码,给其他 Agent 派活 |
| 闭环 | 20XX? | 监督与验证 | 自己训练和构建模型 |
这个阶段的划分不是理论推演,而是 Anthropic 内部真实发生的事情。注意最后那个 20XX?——连 Anthropic 自己都不确定时间点,但方向是明确的。
外部证据:基准测试的加速饱和
如果你只看公开数据,趋势同样惊人。
AI 能完成的任务时长每 4 个月翻一倍(之前是每 7 个月)。这是什么概念?
- 2024 年 3 月:Claude Opus 3 能完成人类约 4 分钟 的任务
- 2025 年 3 月:Claude Sonnet 3.7 搞定 1.5 小时 的任务
- 2026 年 3 月:Claude Opus 4.6 搞定 12 小时 的任务
- 如果趋势持续:2026 年内可能覆盖数天级别的任务,2027 年可能覆盖数周级别的任务
几个重要基准测试的状态:
- SWE-bench(真实世界的软件工程测试):两年内从个位数跑到饱和。模型拿到真实的开源代码库和真实的 bug 报告,自己写修复代码并通过项目测试
- CORE-Bench(复现已有研究):从 2024 年约 20% 的成功率,15 个月后饱和
- METR 长任务基准:Claude Mythos Preview 能连续工作至少 16 小时,已经触及 METR 能测量的上限
来自 Anthropic 内部的数据
公开基准测试能告诉你模型有多强,但看不到 AI 对 AI 开发本身的加速效应。Anthropic 这次公开了内部数据,这是这篇文章最有价值的部分。
80% 的代码由 Claude 编写
截至 2026 年 5 月,Anthropic 合并到代码库的代码中超过 80% 由 Claude 编写。Claude Code 在 2025 年 2 月发布之前,这个数字只有低个位数。
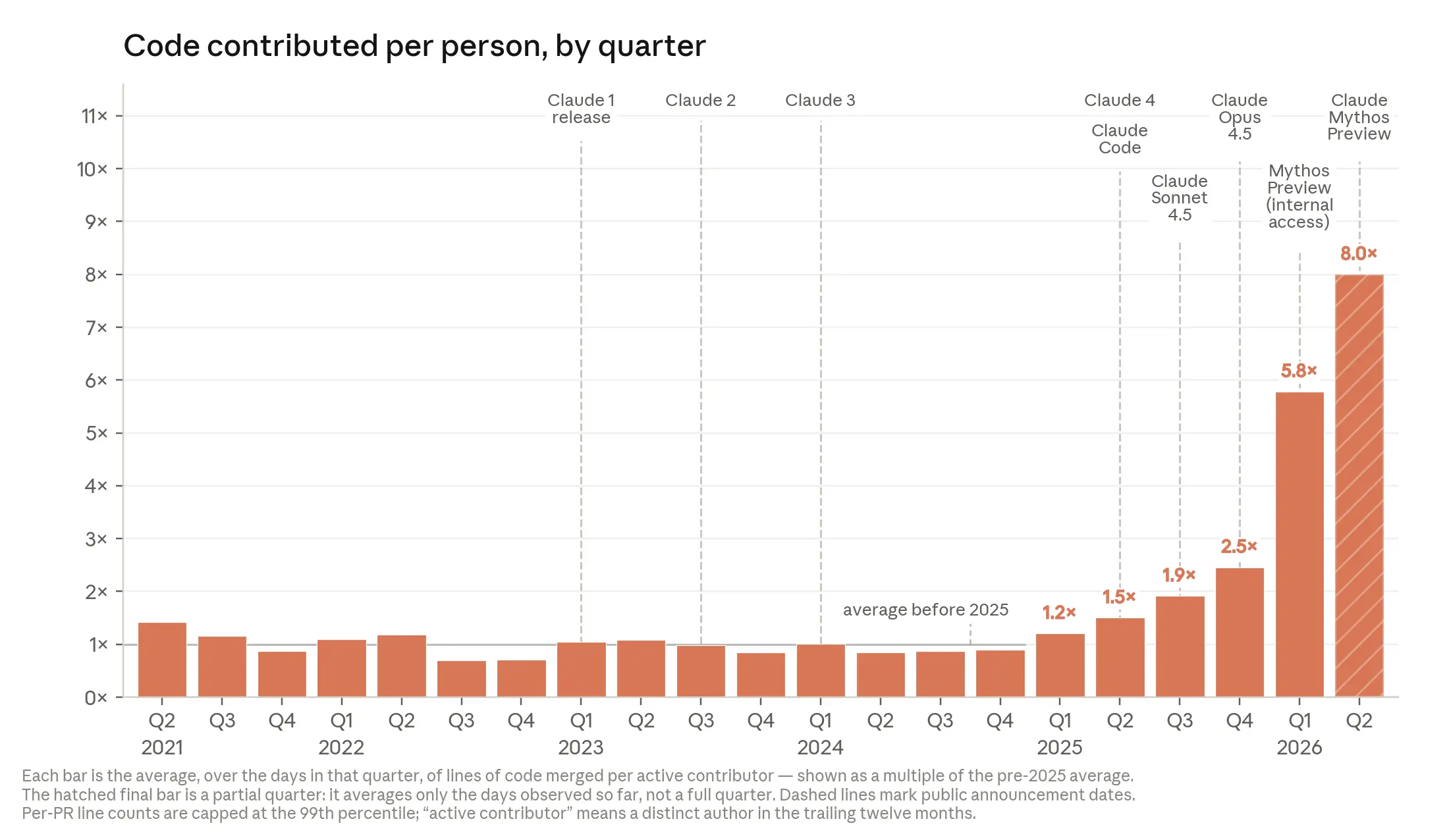
这张图有两个拐点:
- 2025 年初:Claude 开始自己运行代码(而不是让人类复制粘贴),代码量开始上升
- 2026 年:模型开始自主工作更长时间,曲线陡然加速
2026 年 Q2,典型工程师每天合并的代码量是 2024 年的 8 倍。注意,代码行数是不完美的度量——它度量的是数量而非质量。但方向是明确的。
一个更直观的数字:2026 年 3 月,130 名 Anthropic 研究人员的调查显示,中位数受访者估计使用 Mythos Preview 后产出约为不使用 AI 时的 4 倍。
代码质量已接近人类水平
代码质量有两个维度:能用 和 可维护。
在"能用"这个维度上,证据已经非常清楚。Anthropic 员工纠正、重定向或接管 Claude 的频率持续下降——包括最复杂、最开放的任务。
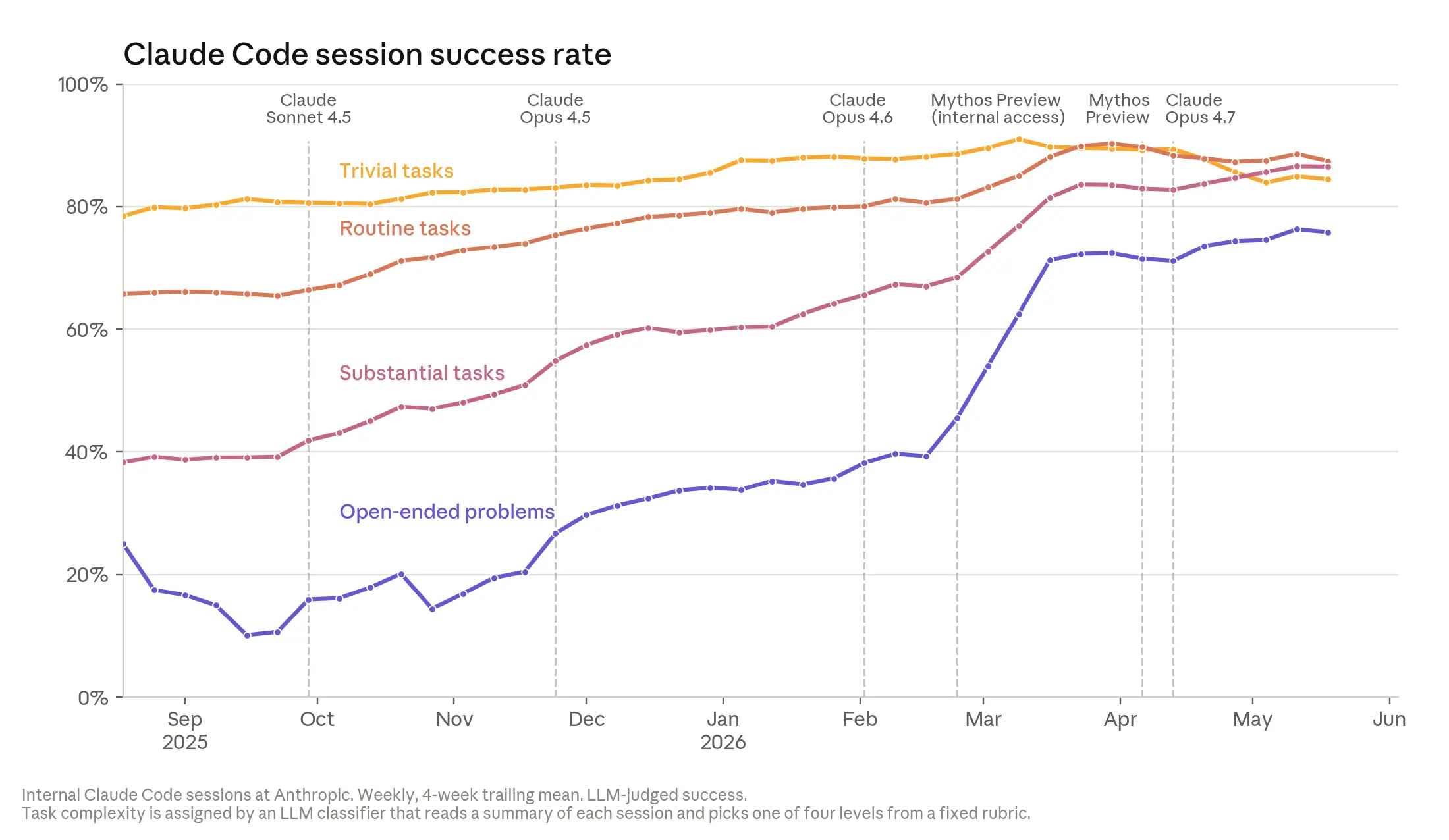
在开放性任务上,Claude 的成功率在 2026 年 5 月达到 76%,六个月内提升了 50 个百分点。
一个具体的例子:一次常规升级导致数万个训练任务崩溃。工程师把现场信息丢给 Claude,Claude 在大约两小时内隔离了一个冷门的调试 flag,可靠地复现了问题并确认了修复。这通常是两到三天的工作量。
在"可维护"这个维度上,差距在快速收窄。Anthropic 内部普遍认为:Claude 写的代码在 2025 年底还不如人类,目前已经基本持平,预计年内将超过人类水平。
一个有趣的发现:Anthropic 用 Claude 自动审查代码变更,回溯分析发现,如果一直用 Claude 审查,它能在大约三分之一的 bug 进入生产环境之前就发现它们。而写出那些代码的工程师,是世界上构建这类系统最顶尖的一批人。
实验优化:从超有用到超人类
Anthropic 每次发模型都跑一个固定测试:给 Claude 一段训练小型 AI 模型的代码,让它尽可能加速同时保持正确性。
- 2025 年 5 月,Claude Opus 4:约 3x 加速
- 2026 年 4 月,Claude Mythos Preview:约 52x 加速
- 对比:一个熟练的人类研究员需要 4–8 小时才能达到 4x
在明确目标下的实验执行这个环节,Claude 在不到一年内从"超有用"变成了"超人类"。
研究判断力:最后的差距
但实验执行和实验设计是两回事。Anthropic 做了一个实验来衡量这个差距:
他们找了 129 个真实的研究会话,这些会话都有一个共同特点——研究员在某个时刻走了一个弯路。他们把这个弯路之前的内容截断,问各个 Claude 模型"你下一步会怎么做",然后用一个能看到完整会话结果的 Claude 来判断:AI 和人类谁的选择更好?
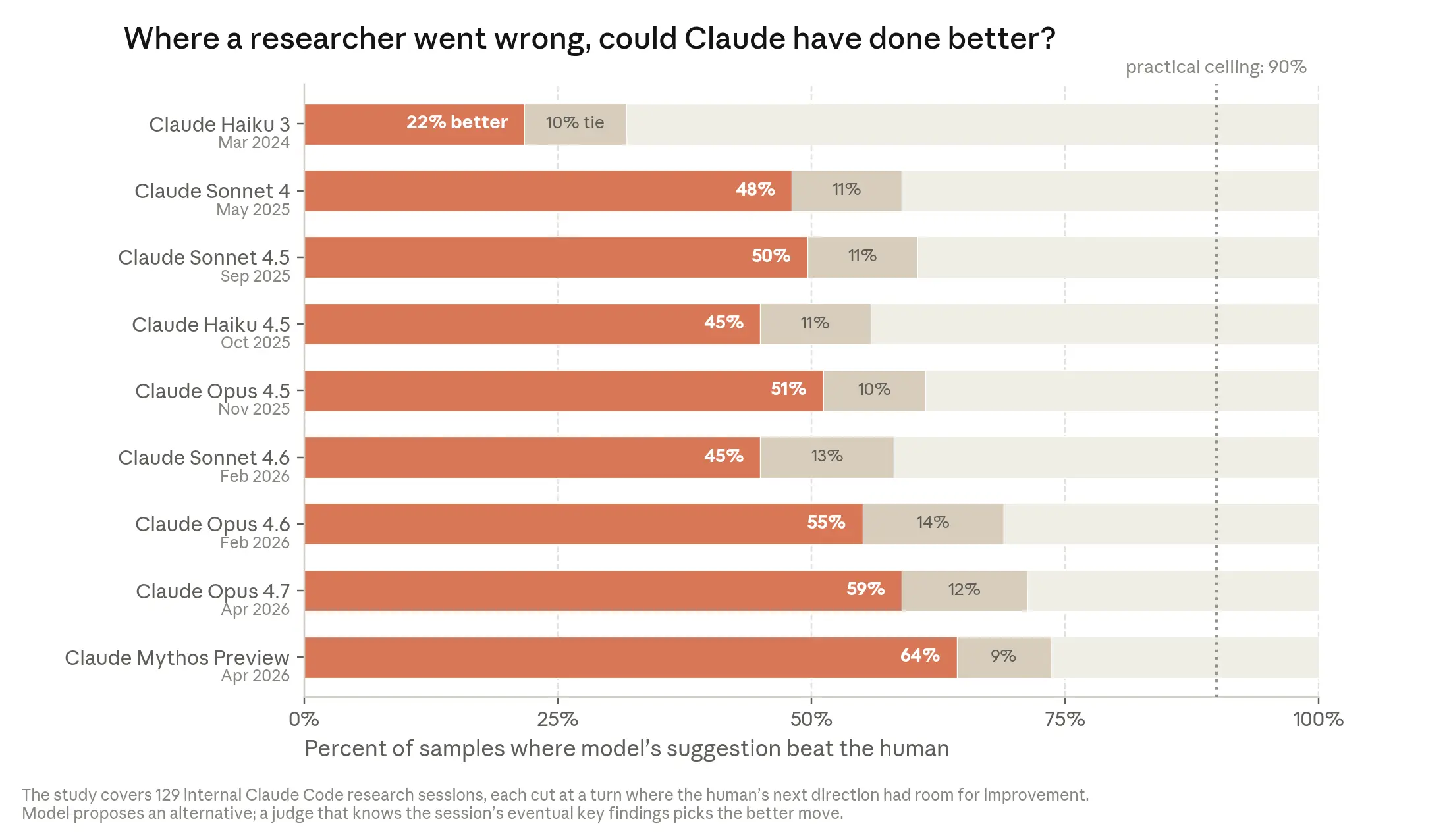
结果:
- 2025 年 11 月,Claude Opus 4.5:51% 的情况下比人类选择更好
- 2026 年 4 月,Claude Mythos Preview:64% 的情况下比人类选择更好
注意,这组数据本身就偏向 AI——因为他们刻意挑选了人类判断有改进空间的时刻。但作为一个衡量 AI 研究判断力随时间提升的指标,方向是清晰的。
这就是 AI 今天和"能自主设计自己继任者"之间的差距:方向设定——选择什么问题值得研究、什么结果值得信任、什么时候该放弃一条路。
三种未来场景
Anthropic 提出了三种可能的未来:
场景一:趋势停滞,但当前能力广泛扩散
指数曲线可能实际上是 S 曲线,我们可能正在接近拐点。"研究品味"可能是一种无法通过扩大训练来获得的能力。或者瓶颈可能在供应链——芯片产能、电网扩张、互联带宽。
即使模型能力冻结在今天的水平,变革仍然巨大。Project Glasswing 项目中,Mythos Preview 在最初几周就发现了全球最重要系统中超过一万个高危软件漏洞。一个 100 人的公司将能完成过去 1000 人的工作。
Anthropic 认为这个场景可能性最低——因为他们观察到每一个可衡量的能力指标都在同一条上升曲线上,还没有看到曲线变平的迹象。
场景二:AI 实验室持续获得复合效率增益
AI 开发被大幅自动化,但人类继续设定研究方向。100 人的公司能做 10,000 甚至 100,000 人组织的工作。
但这里有 Amdahl 定律的影子:加速一部分流程只会把瓶颈推到其他地方。Anthropic 已经遇到了这个问题——随着代码量暴增,人类的代码审查成了新的瓶颈。同样,新想法、新工具、新模拟的爆炸式增长远远超出了他们能追求的范围。
识别和修复瓶颈的能力,可能成为任何组织最重要的能力。
场景三:AI 系统实现完全的递归自我改进
AI 开始设计和精炼自身。进步的速度完全由算力可用性决定。人类角色大幅缩减,主要转向监督、验证和确认一个不断扩展的"虚拟实验室"。
这个场景最不确定的部分是对齐问题:
- 模型可能足够对齐且有足够的研究品味,发现并实施人类尚未达到的新方案
- 也可能够聪明到在不确定时主动暂停开发
- 但也可能——今天模型中罕见的不对齐行为在构建继任者时复合增长,变得越来越频繁却越来越不被理解,直到人类失去控制
Anthropic 的立场:我们需要暂停的选项
文章最后提出了一个明确的政策立场:
如果有可能有效地减缓这项技术的发展,给我们更多时间来处理其巨大影响,我们认为这可能是好事。但如果减速只是让最不谨慎的参与者在技术上赶上来,可能会让每个人都更不安全。
Anthropic 明确表示:如果其他前沿开发者也能以可验证的方式减速或暂停,他们愿意这样做。
但实现可信的暂停极其困难:
- 训练运行比导弹发射井更容易隐藏
- 训练的输入是通用资源(算力、电力)
- 悄悄违约的激励巨大——谁在别人暂停时继续,谁就能继承领先地位
- 暂停还需要定义触发条件、解除条件和裁决机制
Anthropic 承诺在未来几个月组织政策制定者、研究人员、公民社会和其他 AI 公司的对话,推动这些问题——特别是围绕完全递归自我改进和如何创建更好的协调选项。
我的思考
几点个人观察:
1. "8 倍代码量"是一个被低估的数字。 因为这不只是"写了更多代码"——它改变了工程师的角色定义。工程师从"写代码的人"变成了"审查和引导 AI 的人"。当审查速度跟不上生成速度时(Amdahl 定律),整个流程会再次重组。
2. 研究判断力的进步是最值得关注的指标。 代码编写和实验执行已经接近或超过人类水平,但"决定研究什么"这个最后的人类堡垒正在缩小——从 51% 到 64% 的胜率提升只用了五个月。如果这个趋势持续,"研究品味"可能也只是另一种 AI 能力——AI 会失败一段时间,然后突然变好。
3. 三种场景的分布比结论更重要。 Anthropic 明确说他们认为场景一最不可能。但他们没有押注场景二还是场景三——这本身就是一种信号。如果他们确信递归自我改进不会发生,他们会说"我们距离场景三还很远"。他们没有这么说。
4. 暂停的悖论。 Anthropic 愿意暂停的前提是"其他人也暂停"。但在一个没有全球协调机制的世界里,这几乎等同于"我们不暂停"。这不是批评——这是一个真实的囚徒困境。文章在这一点上非常诚实。
5. 最被低估的风险:不是 AI 变得强大,而是人类的协作基础设施被侵蚀。 文章引用了一位 Anthropic 员工的话让我印象深刻:
工作和生活曾经运行在人与人之间的小恩小惠的礼物经济上。"你能帮我跑一下这个脚本吗?"……每一个请求都创造了一点人情债、一点相互认知。Claude 更快,不产生人情债,但每一个这样的请求都是一次人类协作机会的丧失。
当 AI 让每个请求都能被即时满足时,人与人之间的协作纽带也在被悄无声息地削弱。这不是技术问题,而是社会结构问题。
原文核心数据速查
| 指标 | 数值 |
|---|---|
| Claude 编写的代码占比 | > 80%(2026 年 5 月) |
| 工程师代码产出提升 | 8x(对比 2024 年) |
| 研究员自评产出提升 | ~4x(使用 Mythos Preview) |
| 开放性任务成功率 | 76%(2026 年 5 月,六个月提升 50 个百分点) |
| 实验优化加速 | 从 3x(Opus 4)到 52x(Mythos Preview) |
| 研究判断力超越人类 | 64% 的时刻模型建议优于人类(Mythos Preview) |
| 任务时长翻倍周期 | ~4 个月(从 ~7 个月加速) |
| Claude 一次性修复量 | 800+ 修复将某类 API 错误降低 1000 倍 |
本文基于 Anthropic Institute 2026 年 6 月发布的 When AI builds itself 撰写,包含个人解读和分析。