

如果你已经习惯通过 BAMD 写代码,接下来真正耗时间的,往往不是“写”,而是“协调”。
一个 Epic 里有 5 个、10 个、20 个 Story。每个 Story 都要经历创建规格、开发实现、自动化测试、代码审查、回顾总结。真正让人疲惫的,不是某一步本身,而是你要不断盯着流程、切换会话、处理失败、决定下一步。
Story Automator 想解决的,就是这层“人肉编排”。
昨晚我实际跑了一遍 /bmad-story-automator 的完整流程。下面就是这次使用过程的记录,以及一些当时截下来的图。
它解决的不是“写代码”,而是“盯流程”
先用一句话概括 Story Automator:
你告诉它要处理哪些 Story、用什么执行策略,它就自动完成「创建规格 → 开发实现 → 测试自动化 → 代码审查 → 回顾」这条流水线,只在真的需要人类决策时才打断你。
这和普通“单命令跑一个 Skill”不一样。它更像一个构建周期编排器:
初始化
→ 读取 Epic / Sprint 状态
→ 选择 Story 范围
→ 评估复杂度
→ 选择 Agent 策略
→ 执行 create / dev / automate / review / retro
→ 在失败或冲突时升级给人类
从设计上说,它是在自动化“协调工作”,而不是直接替代某一个具体开发步骤。
升级BMAD到最新版(v6.6)
如果你想体验 Story Automator,需要先把 BMAD 升到 6.6。安装时记得把 BMad Automator (Experimental) 这个模块勾上。

不然装完 BMAD,后面是用不起来的。
第一次运行:先补齐 Stop Hook,防止工作流半路被打断
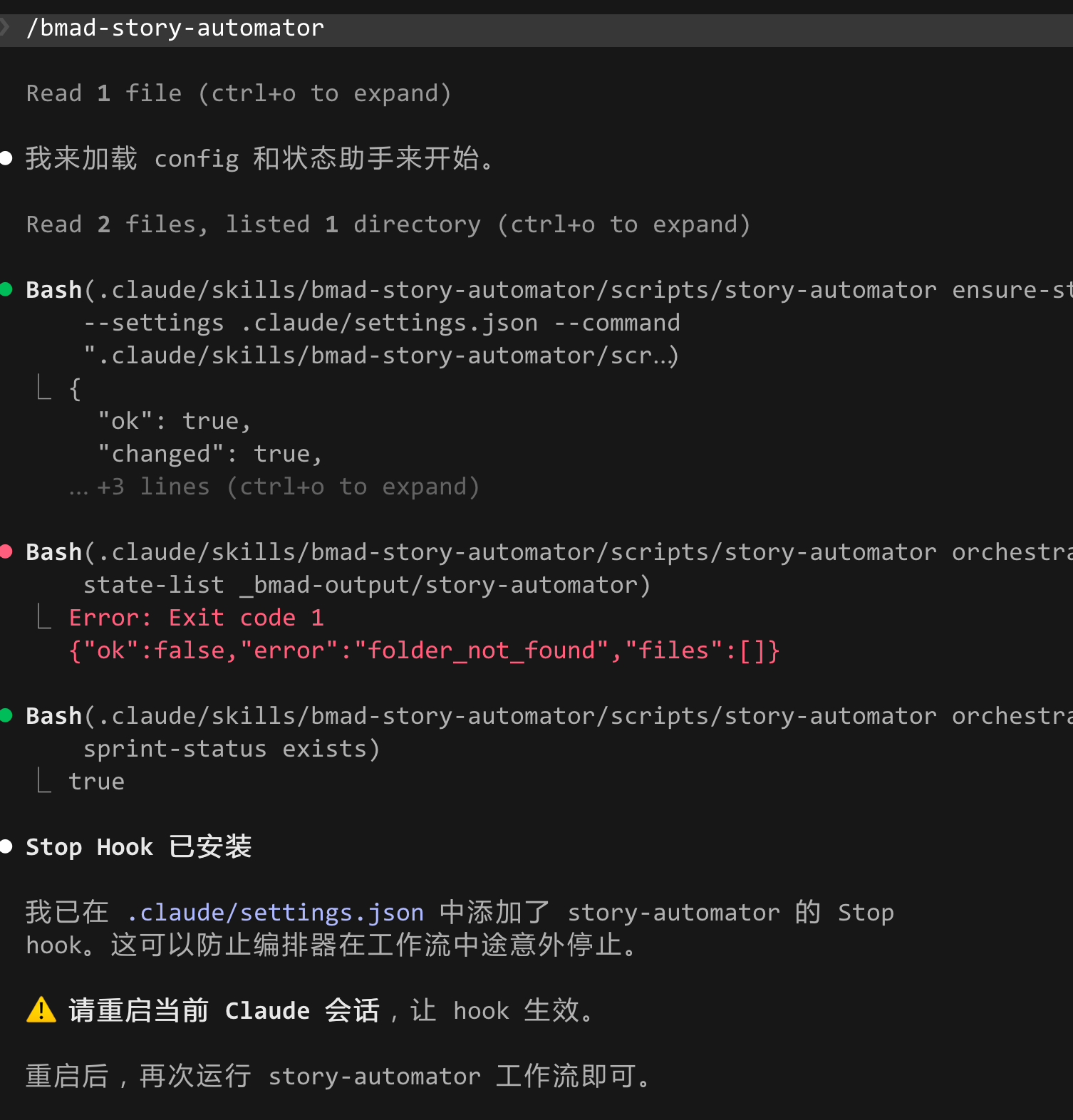
第一次执行 /bmad-story-automator 时,它不会急着开跑,而是先做初始化检查。
从下面这张图可以看到,它先加载配置,然后尝试读取当前编排状态;如果发现状态目录还不存在,这是正常的首次运行场景。接着它会自动安装 Stop Hook 到 .claude/settings.json 中。
第一步:先选 Story,不是盲跑所有待办项
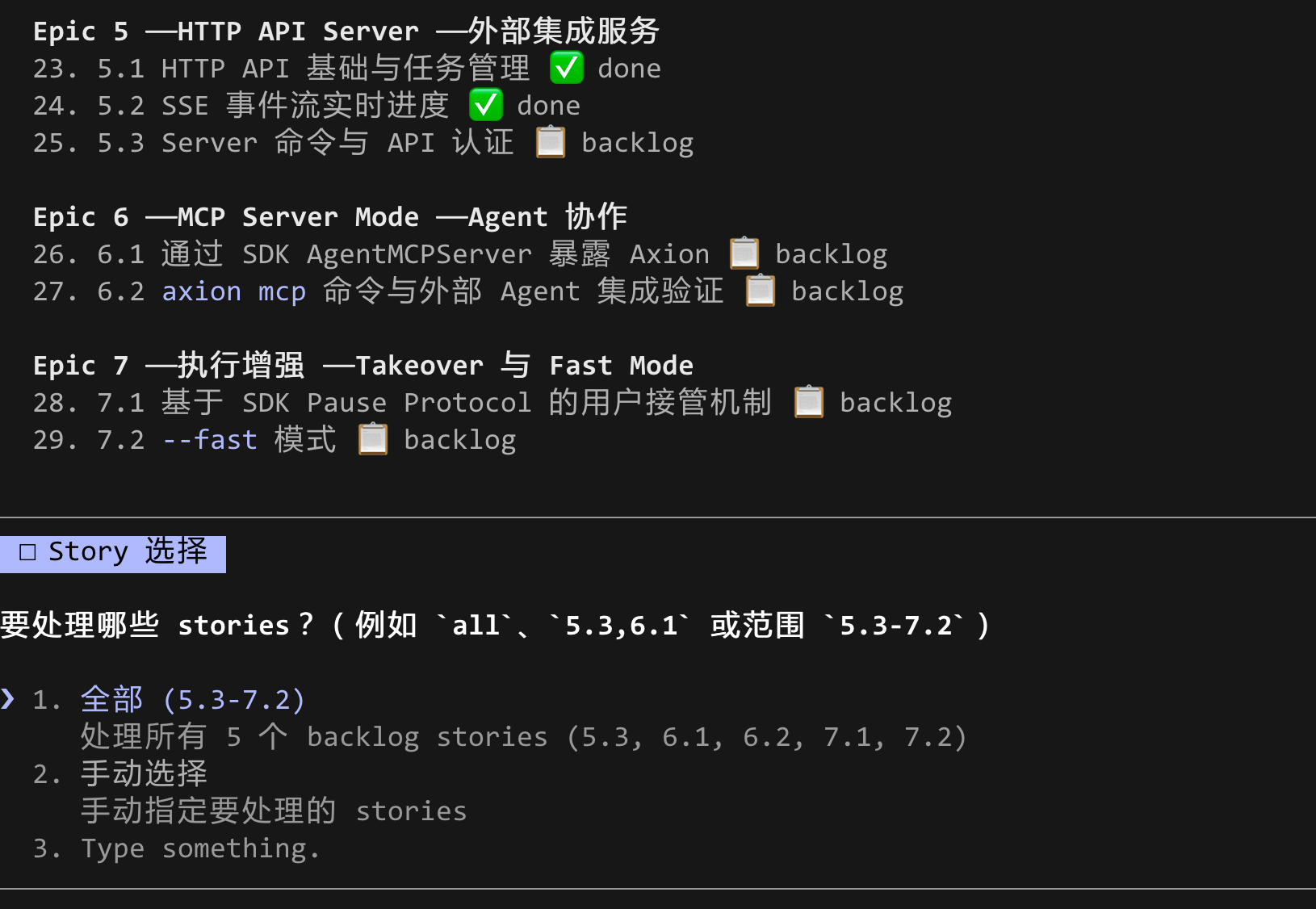
真正进入编排前,Story Automator 会先读取 Epic 和 sprint 状态,然后让你决定处理范围。
下面这张图展示了一个很典型的场景:Epic 5、6、7 中一部分 Story 已完成,一部分仍然待办。工具会把这些状态直接展示出来,然后询问你要处理哪些 Story。
第二步:复杂度不是拍脑袋,而是先打分再分配 Agent
这是我觉得 Story Automator 最有意思的部分之一。
它不是把所有 Story 一股脑丢给同一个 Agent,而是先生成一个Story 复杂度矩阵。截图里可以看到:
- Story 5.3 “Server 命令与 API 认证” → 4 分 / Medium
- Story 6.1 “通过 SDK AgentMCPServer 暴露 Axion” → 2 分 / Low
- Story 6.2 “axion mcp 命令与外部 Agent 集成验证” → 2 分 / Low
- Story 7.1 “基于 SDK Pause Protocol 的用户接管机制” → 2 分 / Low
- Story 7.2 “--fast 模式” → 5 分 / Medium
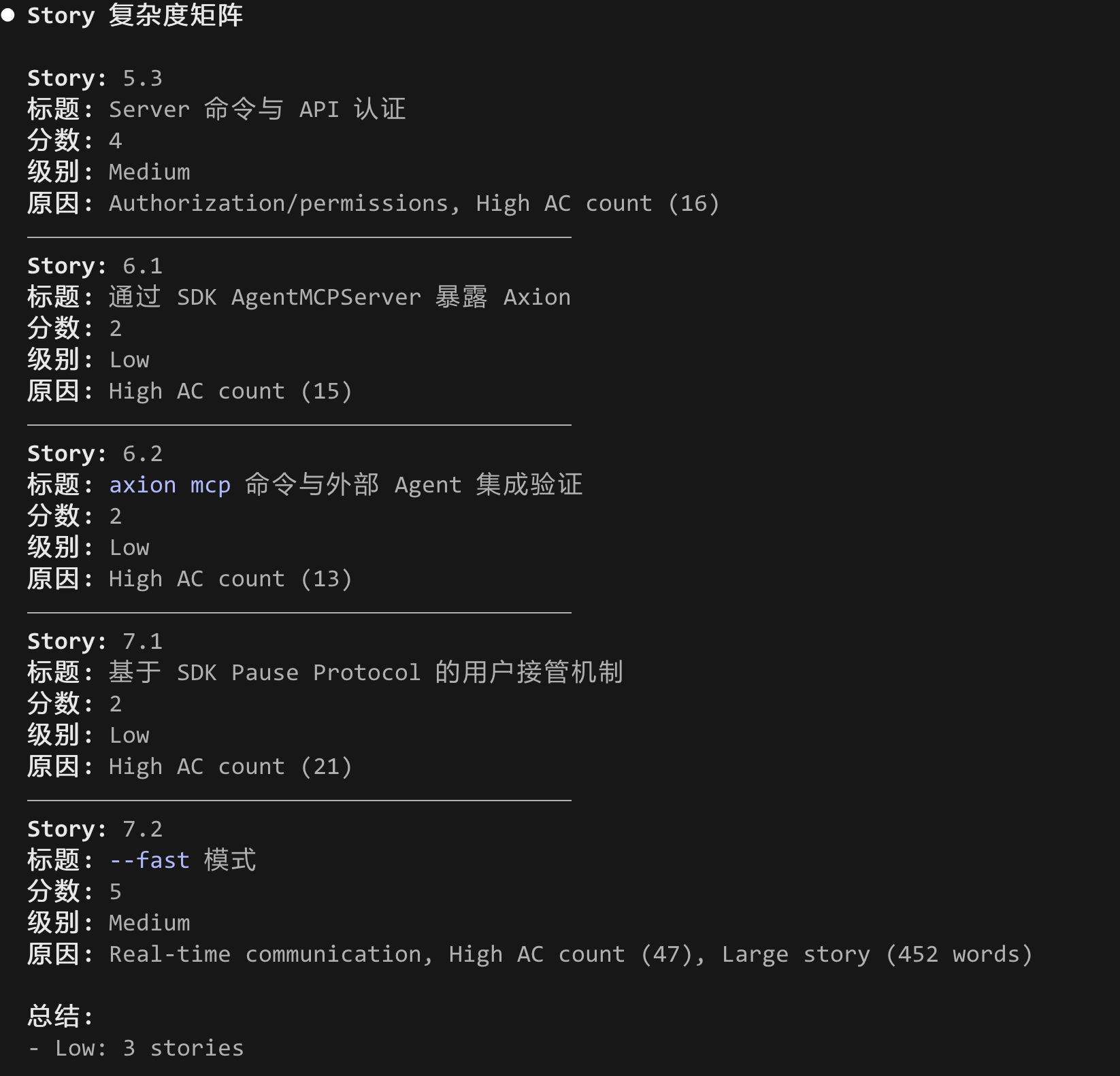
更关键的是,它不只给分,还给出原因:
- authorization / permissions
- 实时通信
- 验收标准数量高
- Story 文本较大
这意味着复杂度评估不是黑盒。你看到的不只是“结论”,而是“为什么它觉得这个 Story 更难”。这会直接影响后续的 Agent 选择策略。
换句话说,Story Automator 在做的事其实是:
先把 Story 变成“可调度对象”,再决定谁来执行。
第三步:你可以塞入自定义指令,但默认不强迫你多想
接下来它会问你有没有自定义指令。

比如:
- 每次修改后都运行测试
- 优先处理某个 Story
- 注意数据库迁移
这个设计我很喜欢,因为它在“全自动”和“可控”之间找到了一个不错的平衡:
- 如果你没有特殊要求,直接选
none - 如果你有本轮迭代的偏好,可以临时注入
也就是说,它把“人类经验”当成一种可选输入,而不是每次都强迫你从头配置一大堆参数。
第四步:执行设置决定它跑得多激进
再往下,就是执行策略层面的配置。截图中可以看到两个核心问题:
- 是否跳过
automate步骤(测试自动化) - 最大并行会话数是多少

默认值是:
- 不跳过 automate
- 最多 1 个并行会话
对大多数真实项目来说,测试自动化是交付闭环里最不该轻易跳过的一环;而并行度默认设为 1,也避免了多个会话同时改动同一代码库时互相干扰。也就是说:
默认先追求“可控完成”,而不是“并行冲刺到极限”。
第五步:不同复杂度,自动映射到不同 Agent
有了复杂度矩阵之后,Story Automator 就能推荐 Agent 配置。
推荐配置如下:
- Low:create / dev / auto / review 都用 Claude
- Medium:create / dev / auto / review 都用 Codex,Claude 作为备选
- High:同样以 Codex 为主
- Retro:回顾阶段使用 Claude

从这个配置可以看出,它已经不是“调用一个模型”的层面了,而是在做模型编排。
而且它还提供了策略选项:
- Suggested:采用按复杂度分层的推荐配置
- Uniform:所有 Story 都使用同一个 Agent
不同团队可以这样用:
- 想稳一点,按推荐走
- 想保持行为一致,就统一 Agent
而从后面的配置摘要截图也能看出来,这次实际演示最后保存成了 all-claude。这恰好说明:推荐是推荐,不是强制。 你既可以让系统按复杂度智能分配,也可以为了稳定性或一致性,手动统一到同一类 Agent。
这一步让整个系统更像一个“调度器”,而不是一个简单的命令包装器。
第六步:配置会被显式保存,方便恢复和复盘
当你确认后,Story Automator 会把这次运行配置保存下来。截图里展示的是一个名为 all-claude 的配置摘要:

摘要里写了几件事:
- Epic 是哪个
- Story 范围是什么
- 自定义指令有没有
- create / dev / auto / review / retro 分别用什么 Agent
- 是否跳过自动化
这类“摘要页”看起来很普通,但它是编排器可恢复、可审计、可复盘的基础。
因为自动化一旦跨越多个 Story、多次会话、多个阶段,就一定会面对这些问题:
- 中途停了怎么办?
- 我这次到底选了什么配置?
- 为什么这批 Story 用的是这个 Agent 组合?
有了显式保存的配置,后续无论是恢复执行还是事后分析,都不会变成猜谜游戏。
实际体验结论
昨晚睡觉前,我直接把这 5 个 Story 交给 Story Automator 去跑。早上起来看结果,它总共跑了 5 个半小时。
坦白说,速度是比我自己手工盯着跑要慢的。按我平时的节奏,这 5 个 Story 如果自己来,估计 3 个小时内能收完。至于为什么会慢这么多, 具体原因还不太清楚, 还没有仔细的去分析它的实现原理,不过目前还只是试验版,能跑通比较重要。
目前比较适合:睡觉前梭一把。
另外一个我觉得做得不错的点,是每个 Epic 跑完之后,它会顺手做一次复盘,把有用的信息补到 project-context.md 里。
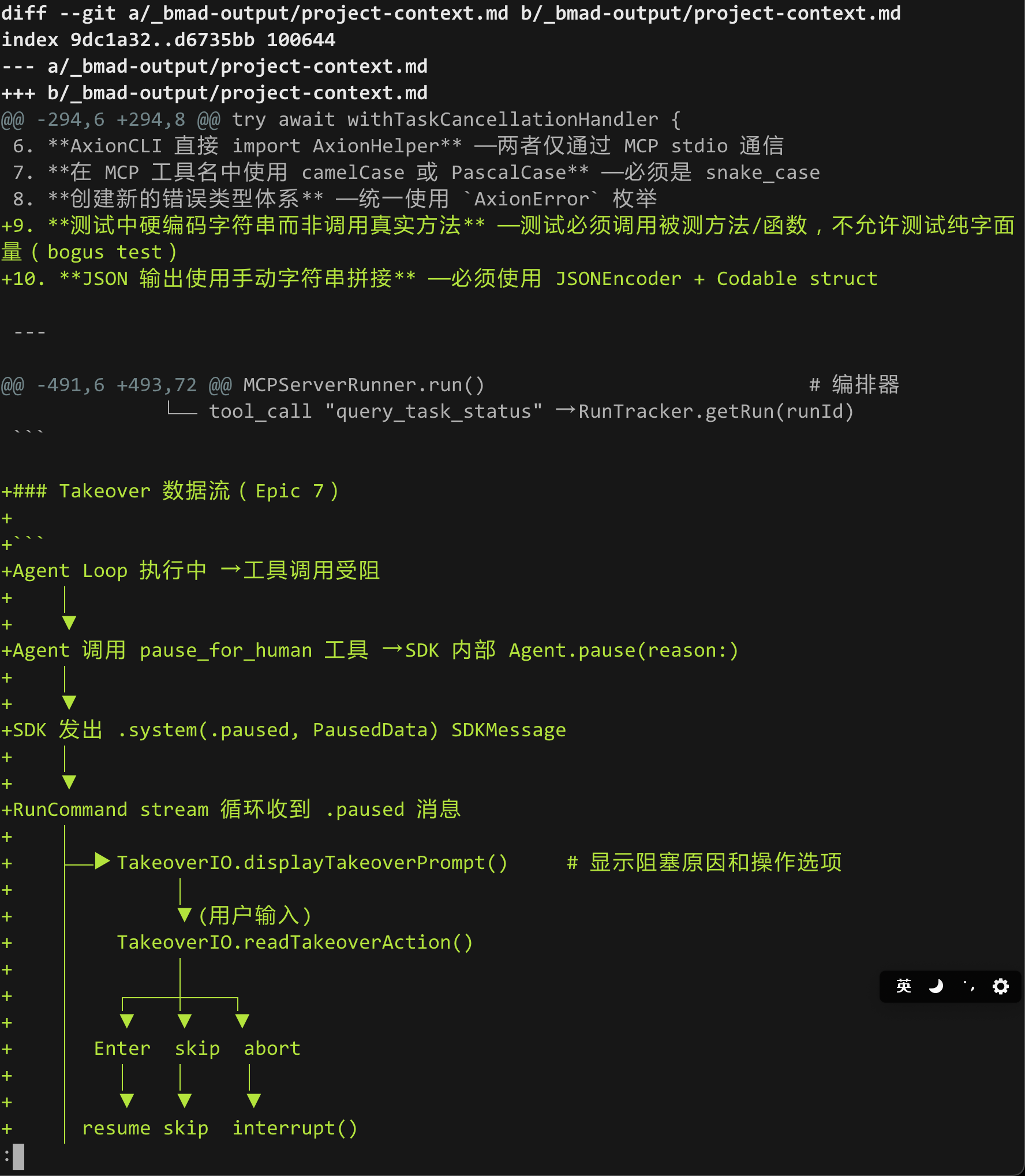
所以我现在对它的看法很简单:
白天手工跑,目前还是自己手工跑会更快。
但睡前把一批 Story 交给它过夜跑,这个场景它真的挺合适。
如果你正在使用 BMAD 来开发项目,你一定要试一下 Story Automator,它可能是你将重复协调时间从小时级降到分钟级的工具。